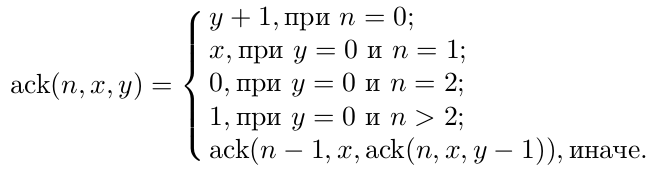
На 2-м курсе по специальности АСОиУ читается 2-семестровая дисциплина Алгоритмические языки. Обзорно рассмотриваются несколько дюжин языков программирования. Один из студентов, Вадим Шукалюк, захотел получше с ними познакомиться, получить более четкое представление о каждом из них. Преподаватель посоветовал ему провести небольшое исследование. Предлагаю свой отчёт по проделанной за несколько месяцев вместе с ним работе.
У каждого языка программирования есть свои достоинства и недостатки. Одна из важнейших характеристик транслятора с любого языка — это скорость исполнения программ. Очень трудно или даже невозможно получить точную оценку такой скорости исполнения. Ресурс http://benchmarksgame.alioth.debian.org/ предлагает игровую форму для проверки такой скорости на разных задачах. Но число языков, представленных на этом ресурсе, довольно невелико. Предельную ёмкость стека, критическую величину для рекурсивных вычислений, проверить проще, но она может меняться в разных версиях транслятора и быть зависимой от системных настроек.
Тестировались следующие трансляторы: си (gcc, clang, icc), ассемблер (x86, x86-64), ява (OpenJDK), паскаль (fpc, ack), яваскрипт (Google Chrome, Mozilla Firefox, node), лисп (sbcl, clisp), эрланг, хаскель (ghc, hugs), дино[1], аук (gawk, mawk, busybox), луа, рубин, бейсик (gambas, libre office), питон-2, пи-эйч-пи, постскрипт (gs), пролог (swipl, gprolog), перл, метапост, ТEХ, тикль, бэш, сед (GNU sed), эм-эс-и[2]. Все трансляторы за исключением случаев ассемблера x86 и ack 64-разрядные. Исследовались как собственно скорость исполнения нескольких небольших, но трудоёмких алгоритмов, так и:
В качестве первой задачи, на которой тестировались все трансляторы, выбран расчёт числа Фибоначчи двойной рекурсией согласно определению: числа с номерами 1 и 2 — это единицы, а последующие — это сумма двух предыдущих. Этот алгоритм имеет несколько привлекательных особенностей:
Первая особенность позволяет за небольшое время протестировать трансляторы, скорости работы которых различаются в сотни тысяч раз. Вторая особенность позволяет быстро проверять правильность расчетов. Третья особенность теоретически позволяет исследовать ёмкость стека, но из-за того, что расчет при n > 50 становится очень медленным даже на суперкомпьютере, практически использовать эту особенность не представляется возможным.
В следующей таблице 1 во второй колонке указывается название языка, название компилятора и его версия и, если использовалась, опция оптимизации генерируемого кода. В третьей колонке приводится относительное время вычисления на процессоре AMD Phenom II x4 3.2 ГГц. Тесты проводились и на AMD FX-6100 на такой же частоте, но их результаты мало отличаются от приведённых. За единицу прянято время вычисления на языке бэш, таким образом, расчёт на эрланге примерно в 20000 раз быстрее бэш. В 4-й колонке приводится относительное время вычисления на процессоре Intel Core i3-2100 3.1 ГГц. Так как сравнение процессоров не было целью исследования, часть трансляторов не были протестированы на платформе Intel. В пятой — оценка сверху (точность 10%) максимального числа рекурсивных вызовов, поддерживаемых транслятором при вычислении ack(1,1,n) на компьютере с 8 Гб оперативной памяти c размером системного стека (ulimit -s) 8192 КБ. Некоторые трансляторы используют собственные настройки, которые определяют размер используемого стека — всегда используются значения по умолчанию для выбранной версии транслятора. Измерения проводились в системе Linux, но их результаты не должны меняться при переходе к другой ОС. Данные отсортированы по 3-й колонке. Все исходники можно посмотреть здесь.
Табл 1.
| N | Язык | AMD | Intel | Стек |
|---|---|---|---|---|
| 1 | C/C++ (gcc 4.7.2, -O3) | 354056 | 493533 | 790000 |
| 2 | C/C++ (clang 3.0-6.2, -O3) | 307294 | 270000 | |
| 3 | C/C++ (icc 14.0.3, -fast) | 250563 | 232665 | 530000 |
| 4 | Assembler x86-64 | 243083 | 271443 | 350000 |
| 5 | Assembler x86 | 211514 | 301603 | 700000 |
| 6 | Java (OpenJDK 1.7.0_25) | 186401 | 239659 | 8000 |
| 7 | Pascal (fpc 2.6.0, -O3) | 170604 | 186401 | 180000 |
| 8 | C/C++ (gcc 4.7.2, -O0) | 159672 | 173261 | 180000 |
| 9 | C/C++ (clang 3.0-6.2, -O0) | 146726 | 110000 | |
| 10 | C/C++ (icc 14.0.3, -O0) | 136862 | 156602 | 530000 |
| 11 | Javascript (Mozilla Firefox 25) | 121979 | 4200 | |
| 12 | Javascript (Google Chrome 31) | 92850 | 10000 | |
| 13 | Javascript (node 0.10.31) | 78028 | 9500 | |
| 14 | Pascal (ack 6.0pre4, -O4) | 75682 | 290000 | |
| 15 | Lisp (sbcl 1.0.57) | 54925 | 51956 | 31000 |
| 16 | Erlang (5.9.1) | 19845 | 18589 | предела нет |
| 17 | Haskell (ghc 7.4.1, -O) | 18589 | 22946 | 260000 |
| 18 | Awk (mawk 1.3.3) | 6621 | 6306 | 44000 |
| 19 | Lua (5.2) | 6420 | 7075 | 150000 |
| 20 | Ruby (1.9.3) | 5297 | 6969 | 6600 |
| 21 | Dino (0.55) | 5024 | 6420 | 190000 |
| 22 | Basic (Gambas 3.1.1) | 3968 | 4373 | 26000 |
| 23 | Python (2.7.3) | 3678 | 4013 | 1000 |
| 24 | PHP (5.4.4) | 2822 | 3720 | предела нет |
| 25 | Awk (gawk 4.0.1) | 2648 | 2547 | предела нет |
| 26 | Postscript (gs 9.05) | 2355 | 3246 | 5000 |
| 27 | Prolog (swipl 5.10.4) | 1996 | 2407 | 2300000 |
| 28 | Perl (5.14.2) | 1516 | 1670 | предела нет |
| 29 | Prolog (gprolog 1.3.0) | 1116 | 1320 | 120000 |
| 30 | Lisp (clisp 2.49) | 998 | 1023 | 5500 |
| 31 | Awk (busybox 1.20.2) | 981 | 1113 | 18000 |
| 32 | Mse (2.03) [3] | 474 | ||
| 33 | Metafont (2.718281) | 313 | 50 | |
| 34 | Sed (4.2.1) [3] | 294 | ||
| 35 | TEX (3.1415926) | 239 | 333 | 3400 |
| 36 | Metapost (1.504) | 235 | 470 | <4100 |
| 37 | Tcl (8.5) | 110 | 123 | 1000 |
| 38 | Haskell (hugs 98.200609.21) | 82 | 121 | 17000 |
| 39 | Basic (LibreOffice 3.5.4.2) | 20 | 35 | 6500 |
| 40 | bash (4.2.37) | 1 | 0,77 | 600 |
В качестве второй задачи выбрана функция Аккермана в форме, когда к ней сводятся все арифметические операции, т. е. ack(1,x,y)=x+y, ack(2,x,y)=x*y, ack(3,x,y)=xy, ack(4,x,y) — тетрация x и y и т. д.
Эта функция с ростом n растёт очень быстро (число ack(5,5,5) настолько велико, что количество цифр в порядке этого числа многократно превосходит количество атомов в наблюдаемой части Вселенной), но считается очень медленно. Последнее свойство теоретически удобно для тестирования быстродействия. Однако, расчет этой функции требует значительного числа рекурсивных вызовов и большинство тестируемых языков оказалось не в состоянии их поддерживать для вычислений, имеющих заметную длительность. Известно, что вычисление этой функции нельзя свести к итерации. Расчет по этой задаче позволил исследовать максимальную ёмкость стека исследуемых языков: расчёт ack(1,1,n-1) требует n-й вложенности вызовов и очень быстр. В следующей таблице 2 представлены результаты расчета пентации ack(5,2,3), для тех языков, стек которых смог его (вложенность вызовов 65539) выдержать. За единицу скорости выбрано время работы gcc с опцией -O3, т. е. php примерно в 420 раз медленнее.
Табл 2.
| gcc -O3 | 1 |
| asm x86 | 2.15 |
| icc -fast | 2.18 |
| asm x86-64 | 2.36 |
| clang -O3 | 2.76 |
| fpc -O3 | 4.44 |
| gcc -O0 | 7.75 |
| icc -O0 | 8.36 |
| clang -O0 | 9.64 |
| ack -O4 | 10.58 |
| Erlang | 18.51 |
| ghc -O | 50.18 |
| lua | 122.55 |
| php | 423.64 |
| gawk | 433.82 |
| swipl | 766.55 |
| dino | 915.64 |
Идея использовать приведённые две задачи позаимствована из труда Б. В. Кернигана и Р. Пайка "Unix — универсальная среда программирования", где она была использована для тестирования языка hoc[4].
Конечно, при более сложных расчётах, использующих преимущественно средства стандартных библиотек, разница в скорости работы трансляторов была бы намного меньшей.
Время измерялось стандартной командой time, а тогда, когда это было невозможно (браузерный яваскрипт, офисный бейсик) использовались встроенные в язык средства.
По результатам исследования сделаны следующие выводы, некоторые из которых оказались несколько неожиданными:
В заключении несколько слов от студента, начинающего осваивать искусство программирования.
Чтобы написать программы для требуемых расчётов на любом языке, необходимо в первую очередь понять как в конкретном языке объявляются переменные, как построить конструкцию типа if-else и как организовать рекурсию. Свою работу я начал с простого языка Pascal, так как на тот момент знал его лучше всех. После паскаля, я взялся за C, Java и Dino, так как их синтаксисы примерно похожи. С оказался довольно интересным, простым, и в то же время с интуитивно понятными операторами. Ява показался менее удобным, чем си/си++ — надо писать много не относящегося к делу, такого, что могло бы быть взято по умолчанию. Также напряг момент необходимости одинаковости имён класса и файла. От Haskell остались только положительные эмоции. Удобный, понятный и мощный. PHP, язык для разработки веб-приложений, очень похож на С: можно просто вставить код на си с минимальными изменениями и все будет работать так, как надо. Erlang похож по синтаксису на Haskell и немного на Prolog. Тоже довольно приятный и понятный язык, никаких трудностей не возникло. Cинтаксис JavaScript похож на синтасис Java или C. Visual Basic как в офисном, так и GAMBAS исполнении имеет несколько угловатый и неудобный синтаксис, но в целом, с ним было не очень трудно. Затем, после приобретения знаний о базом синтаксисе С и Java, получилось довольно быстро написать код на Python, так как Python схож с С. Никаких проблем не возникло с Lua и его довольно мощными и гибкими конструкциями. У awk также схожее строение с С, довольно быстро удалось его осилить. С лиспом возникли некоторые трудности, как у человека, который до этого изучал С-подобные языки, например, с базовым пониманием префиксной записи. Которая после небольших затрат на освоения, показалась очень удобной, логичной и красивой. После, я перешел на язык логического программирования Prolog, который оказался специфичным, но очень интересным и фундаментальным. Ruby — язык с мощной поддержкой объекто-ориентированного программирования и с очень красивым ярко-красным рубином на иконке оказался превосходным языком: никаких лишних скобок, точек с запятой и прочих ненужных знаков. Один из наиболее запомнившихся. Хотя питон, если не считать конструкций ООП, не менее лаконичен. Perl — хоть и носит название "жемчужина", символом языка является верблюд, что видимо является отсылкой к тому, что верблюд не слишком красивое, но очень выносливое животное, способное выполнять тяжёлую работу. После Ruby опять ставить доллары, скобки и точки с запятой было не очень приятно. Синтаксис местами похож на синтаксис языка терминальной оболочки Bash. Затем я взялся за ассемблер. Здесь были определенные трудности и необходимость понимания работы процессора и его регистров. Удивлению не было предела, когда оказалось, что С справляется с расчётами быстрее чем ассемблер, машинный код! Проблем не возникло с Bash, хоть там и нужно ставить много долларов, а при расчётах и скобок. Язык Metapost/Metafont вызвал некоторые проблемы — там поддерживаются только числа, не большие 4096. Хотя его синтаксис вполне традиционен. У тикля (TCL) тоже довольно традиционный синтаксис, но строчно-ориентированный — это и похожая на bash семантика поначалу очень сбивали с толку. Наиболее сложным показались PostScript. В этом языке синтаксис очень специфичен и без подготовки, интуитивно ничего написать не получится, поэтому пришлось изучать соответствующую литературу и начать тренироваться с самых простейших программок. PostScript был настоящим испытанием: написать двойную рекурсию постфиксной записью лишь при помощи стека, после привыкания ко всем инструментам и возможностям Ruby и C было проблематично. Писать и тестрировать на постскрипте функцию Аккермана, все равно что пытаться покрасить стену зубной щёткой. Но первое место по сложности определенно занимает TEX. Ничего более трудного я не встречал. И без прямой помощи преподавателя одолеть этот язык не получилось бы.
Любопытными оказались данные по размерам стека языков. Чем больше стек языка, тем больше вероятность, что он сможет справиться с функцией Аккермана. Но если программа на каком-то языке не смогла справиться с вычислением ack(5,2,3), это не значит что язык плохой и неудобный. Вполне вероятно, что этот язык мог создаваться для других полезных целей как, например, Metapost или Postscript.
В целом, работа показалась мне очень интересной и сверхпознавательной, например написание одного и того же логического оборота 20 разными способами. Также, понимание принципа работы регистров процессора и написания двойной рекурсивной функции лишь при помощи стека и трех операций: добавить, удалить и прокрутить стек сильно расширило мой кругозор.
Преподавателю некоторые выводы своего студента показались слишком категорическими, но он решил их сохранить как более свежие по сравнению со своими собственными.
[1] — Разработаный в России язык программирования. Ныне его автор — сотрудник компании Red Hat, работающий над совершенствованием коллекции компиляторов gcc. Последния версия дино выпущена в 2007 году.
[2] — Многопоточный редактор (Multistream editor), почти аналог языка CC, сделанного в SIL.
[3] — C mse и sed используется более быстрый (примерно на 15%) алгоритм — результат приводится с этой поправкой. Реализовать функцию Аккермана на этих языках не удалось.
[4] — Этот язык тоже был протестирован, показав результат по скорости между mawk и ghc. Что весьма примечательно, так как hoc делает коды без какой-либо оптимизации.
Вариант статьи опубликован на http://habrahabr.ru/post/254121/, а также в виде тезисов доклада на Международной молодёжной научной конференции 41-е Гагаринские чтения