Количество информации и энтропия. Самосинхронизирующиеся коды. Способы контроля правильности передачи. Алгоритмы сжатия информации.
Сутью передачи данных по некоторому каналу является воспроизведение получателем некоторой (заданной отправителем) функции, например, изменения тока или напряжения во времени. При распространении сигнала происходит его искажение: затухание, искажение формы, смешивание с шумом и пр. Затухание возникает из-за того, что часть энергии сигнала рассеивается, при этом, чем больше длина канала, тем больше затухание. Кроме того, сигналы разных частот затухают не одинаково. Искажение формы сигнала происходит по причине разной скорости распространения сигналов разной частоты. В результате гармоники соседних сигналов могут смешиваться и искажать друг друга. Причиной шума является наличие других источников энергии (кроме передатчика). Источником шума могут быть, например, другие линии передачи данных, силовые электрические кабели, атмосферные явления. Неизбежной разновидностью шума является тепловой шум (при температуре среды больше абсолютного нуля).
Количество информация и энтропия
Источник информации, который может в каждый момент времени находиться в одном из возможных состояний, называется дискретным источником информации. Будем называть конечное множество всех возможных состояний {u1, u2, …, uN} алфавитом источника (N – размер алфавита или число возможных состояний). В общем случае разные состояния ui выбираются источником с разной вероятностью pi, и его можно охарактеризовать совокупностью алфавита и множества вероятностей состояний – ансамблем UN = {u1, p1, u2, p2, …, uN, pN}. Разумеется, сумма вероятностей всех состояний должна быть равна 1.
Введем меру неопределенности состояния источника H(U), удовлетворяющую следующим условиям:
— монотонность: мера должна монотонно возрастать с ростом количества возможных состояний.
— аддитивность: мера, вычисленная для сложного источника, состоящего из двух независимых источников (с размерами алфавитов N и M, тогда размер алфавита сложного источника – NM), должна равняться сумме мер этих двух источников. Согласно условию аддитивности, мера должна удовлетворять соотношению H(UNM) = H(UM)+H(UN).
Кроме того, существует граничное условие: мера неопределенности для источника с размером
алфавита 1 должна равняться 0.
Можно показать, что этим условиям удовлетворяет логарифмическая функция (с произвольным основанием).
Для источника с алфавитом размера N и равновероятными состояниями (pi=1/N для любого i) логарифмическая мера была предложена Р.Хартли в 1928 году и имеет вид: H(UN) = log(N). Предположение о равновероятности состояний источника информации называется моделью Хартли. Если основание логарифма выбрать равным двум, соответствующая единица неопределенности будет соответствовать неопределенности выбора из двух равновероятных событий и называться двоичной единицей или битом (от англ. bit, сокращенного binary digit – двоичная единица).
Модели Хартли недостает учета вероятностей состояний. Если, например, источник имеет два возможных состояния с вероятностями 0.999 и 0.001. Ясно, что мера неопределенности такого источника должна быть меньше 1 бита: есть большая уверенность в выборе первого состояния. Если вероятности состояний отличаются незначительно (например, 0.51 и 0.49), то и мера неопределенности должна измениться незначительно по сравнению с равновероятным случаем.
Таким образом, мера неопределенности должна зависеть от вероятностей состояний источника, от всего ансамбля. Такая модель источника информации называется моделью Шеннона. Мера неопределенности выбора дискретным источником состояния из ансамбля UN называется энтропией дискретного источника информации или энтропией конечного ансамбля:
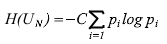
где C – произвольное положительное число.
При равновероятности состояний источника мера Шеннона сводится к мере Хартли.
Доказано, что приведенная функция – единственная, удовлетворяющая всем перечисленным условиям.
Термин “энтропия” был заимствован из термодинамики и использован для меры неопределенности из-за того, что обе энтропии – термодинамическая и информационная – характеризуют степень разнообразия состояний рассматриваемой системы и описываются аналогичными функциями.
Свойства энтропии
– Энтропия является неотрицательной вещественной величиной. Это так, поскольку вероятность лежит в интервале от 0 до 1, ее логарифм отрицателен, а значение (- pi log pi ) положительно.
– Энтропия ограничена сверху значением 1.
– Энтропия равна 0, только если одно из состояний определенный источник).
– Энтропия максимальна, когда все состояния Hmax (UN) = log2 N .
имеет вероятность, равную 1 (полностью
источника равновероятны. При этом
– Энтропия источника с двумя состояниями изменяется от 0 до 1, достигая максимума при равенстве их вероятностей.
– Энтропия объединения нескольких независимых источников информации равна сумме энтропий исходных источников.
– Энтропия характеризует среднюю неопределенность выбора одного состояния из ансамбля, не учитывая содержательную сторону (семантику) состояний.
– Энтропия как мера неопределенности согласуется с экспериментальными психологическими данными. Время безошибочной реакции на последовательность случайно чередующихся равновероятных раздражителей растет с увеличением их числа так же, как энтропия, а при переходе к неравновероятным раздражителям, среднее время реакции снижается так же, как энтропия.
Единицы количества информации
Бит – очень мелкая единица измерения количества информации. Более крупная единица – байт, состоящий из восьми битов. (Восьмибитный байт стал стандартным только с распространением системы IBM System 360 (ЕС ЭВМ), до того в разных вычислительных системах использовались байты разного размера.)
Применяются и более крупные единицы:
Килобайт (Кбайт) – 1024 байт – 210байт
Мегабайт (Мбайт) – 1024 Кбайт – 220 байт
Гигабайт (Гбайт) – 1024 Мбайт – 230 байт
Терабайт (Тбайт) – 1024 Гбайт – 240 байт
Петабайт (Пбайт) – 1024 Тбайт – 250 байт
В качестве единицы количества информации можно было бы выбрать количество информации, содержащееся, например, в выборе одного из десяти равновероятных сообщений. Такая единица будет называться дит или десятичной единицей.
Качество обслуживания
Качество обслуживания (Quality of Service, QoS) сетью потребителя ее услуг определяется, в основном, производительностью и надежностью. Производительность характеризуется следующими основными параметрами:
– Время реакции сети – интегральная характеристика сети с точки зрения пользователя – интервал времени между возникновением запроса пользователя к сетевой службе и получением ответа на этот запрос.
– Пропускная способность или скорость передачи данных – объем данных, переданных за единицу времени. Пропускная способность может, измеряться в битах в секунду (бит/c) или в пакетах в секунду. Различают среднюю, мгновенную и максимальную пропускную способность.
– Задержка доставки данных – время от передачи блока информации до его приема. Часто задержку передачи (вносимую каким-либо сетевым устройством) определяют как интервал времени между моментом поступления пакета на вход сетевого устройства и моментом появления его на выходе этого устройства. Обычно качество сети характеризуется максимальной задержкой передачи и вариацией задержки.
– Надежность оценивается, среди прочих, следующими характеристиками:
– Коэффициент готовности – доля времени, в течение которого система может быть использована. – Уровень ошибок – определяется как вероятность безошибочной передачи определенного объема данных. Например, вероятности 0,99999 соответствует 1 ошибочный бит на 100000 переданных битов. Для локальных сетей характерен уровень ошибок 1 на 108-1012бит.
Максимальная скорость передачи для канала без шума (идеальный случай), согласно теореме Найквиста, составляет 2Hlog2V, где H – пропускная способность, V – количество различаемых уровней сигнала.
Для реальных каналов (с шумом) максимальная скорость передачи определяется по теореме Шеннона: Hlog2(1+S/N), где S/N – отношение мощности полезного сигнала с мощности шума (“отношение сигнал-шум”).
Кодирование информации
При передаче цифровой информации с помощью цифровых сигналов применяется цифровое кодирование, управляющее последовательностью прямоугольных импульсов в соответствии с последовательностью передаваемых данных. При цифровом кодировании применяют либо потенциальные, либо импульсные коды. При потенциальном кодировании информативным является уровень сигнала. При импульсном кодировании используются либо перепады уровня (транзитивное кодирование), либо полярность отдельных импульсов (униполярное, полярное, биполярное кодирование). В отдельную группу импульсных кодов выделяют двухфазные коды, при которых в каждом битовом интервале обязательно присутствует переход из одного состояния в другое (такие коды позволяют выделять синхросигнал из последовательности состояний линии, то есть являются самосинхронизирующимися).
Наиболее распространены следующие коды:
– NRZ (Non-Return to Zero – без возврата к нулю) – потенциальный код, состояние которого прямо или инверсно отражает значение бита данных
– дифференциальный NRZ – состояние меняется в начале битового интервала для “1” и не меняется при “0”
– NRZI (Non-Return to Zero Inverted – без возврата к нулю с инверсией) – состояние меняется в начале битового интервала при передаче “0” и не меняется при передаче “1”. Используется в FDDI, 100BaseFX.
– RZ (Return to Zero – с возвратом к нулю) – биполярный импульсный самосинхронизирующийся код, представляющий “1” и “0” импульсами противоположной полярности, длящимися половину такта (вторую половину такта состояния устанавливается в нулевое); всего используется три состояния
– AMI (Bipolar Alternate Mark Inversion – биполярное кодирование с альтернативной инверсией) – используется три состояния: 0, + и –, для кодирования логического нуля используется состояние 0, а логическая единица кодируется по очереди состояниями + и –. Используется в ISDN, DSx.
– Манчестерское кодирование (manchester encoding) – двухфазное полярное самосинхронизирующееся кодирование, логическая единица кодируется перепадом потенциала в середине такта от низкого уровня к высокому, логический ноль – обратным перепадом (если необходимо представить два одинаковых значения подряд, в начале такта происходит дополнительный служебный перепад потенциала). Используется в Ethernet.
– Дифференциальное манчестерское кодирование (differential manchester encoding) – двухфазное полярное самосинхронизирующееся кодирование, логический ноль кодируется наличием перепада потенциала в начале такта, а логическая единица – отсутствием перепада; в середине такта перепад есть всегда (для синхронизации). В Token Ring применяется модификация этого метода, кроме “0” и “1”, использующая служебные биты “J” и “K”, не имеющие перепада в середине такта (“J” не имеет перепада в начале такта, “К” – имеет).
– MLT-3 – трехуровневое кодирование со скремблированием без самосинхронизации, логический ноль кодируется сохранением состояния, а логическая единица кодируется по очереди следующими состояниями: +V, 0, -V, 0, +V и т.д. Используется в FDDI и 100BaseTX.
– PAM5 (Pulse Amplitude Modulation) – пятиуровневое биполярное кодирование, при котором каждая пара бит данных представляется одним из пяти уровней потенциала. Применяется в 1000BaseT.
– 2B1Q (2 Binary 1 Quarternary) – пара бит данных представляется одним четвертичным символом, т.е. одним из четырех уровней потенциала. Применяется в ISDN.

Рис. 1. Способы цифрового кодирования данных.
Логическое кодирование
Некоторые разновидности цифрового кодирования очень чувствительны к характеру
передаваемых данных. Например, при передаче длинных последовательностей логических нулей посредством потенциального кода типа NRZ или AMI сигнал на линии долгое время не изменяется, и приемник может ошибиться с моментом считывания очередного бита. Для кода NRZ подобные проблемы возникают и при передаче длинных последовательностей логических единиц. Логическое кодирование (которому может подвергаться исходная последовательность данных) должно внедрять в длинные последовательности бит, биты с противоположным значением, или вообще заменять их другими последовательностями. Кроме исключения “проблемных” битовых последовательностей, логическое кодирование позволяет также увеличить кодовое расстояние между символами (для упрощения декодирования), улучшить спектральные характеристики сигнала, а кроме того передавать в общем потоке служебные сигналы. В основном для логического кодирования применяются три группы методов: вставка бит, избыточное кодирование и скремблирование.
Вставка бит (bit stuffing) – наиболее прямолинейный способ исключения длинных последовательностей, например, логических единиц. Если в передаваемой последовательности встречается непрерывная цепочка “1”, то передатчик вставляет “0” после каждой, например, пятой “1”. Приемник отбрасывает все эти лишние “0”, которые встречаются после пяти “1”. Разумеется, можно проводить и обратную операцию – вставку “1” в длинные последовательности “0”. Схема вставки бит применяется, например, в протоколе HDLC.
Избыточное кодирование основано на разбиении исходной последовательности бит на участки одинаковой длины – символы. Затем каждый символ заменяется (как правило, табличным способом) на новый, имеющий либо большее количество бит, либо другое основание системы счисления (например, на символ, состоящий из троичных разрядов). Рассмотрим некоторые распространенные схемы логического кодирования.
Логический код 4B/5B заменяет каждые 4 бита входного потока (исходный символ) на 5-битный выходной символ. Так как количество различных 5-битных символов равно 32, а исходные символы могут содержать лишь одну из 16 битовых комбинаций, среди возможных выходных кодов можно отобрать 16 “удобных” комбинаций – не содержащих большого количества нулей (больше трех подряд), среди оставшихся кодов выделить служебные символы (для поддержания синхронизации, выделения границ кадров и их полей и т.д.), а оставшиеся коды считать запрещенными.
Таблица 1. Код 4B/5B
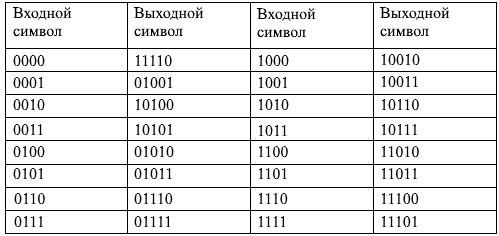
Накладные расходы при кодировании 4B/5B составляют 25% (один лишний бит на четыре бита данных), соответственно для достижения той же пропускной способности, что и без логического кодирования, передатчик должен работать на повышенной на 25% частоте. Код 4B/5B используется в FDDI и Fast Ethernet: 100BaseFX и 100BaseTX.
Логический код 8B/10B заменяет каждый 8-битный исходный символ 10-битным выходным символом. При том же уровне накладных расходов (25%), что в случае кода 4B/5B, обладает 4-кратной избыточностью (1024 выходных символов и 256 исходных символов). При кодировании 8B/10B каждому исходному символу сопоставлено два выходных символа, выбор из которых осуществляется в зависимости от последнего бита предыдущего переданного символа. В результате код обеспечивает стабильное соотношение “0” и “1” в выходном потоке, независимо от исходных данных. Это свойство важно для лазерных передатчиков, поскольку от данного соотношения зависит их нагрев и количество ошибок приема. Код 8B/10B используется в Gigabit Ethernet: 1000BaseSX, 1000BaseLX, 1000BaseCX.
Логический код 8B/6T кодирует каждые 8 бит исходной информации шестью троичными (T –
ternary, троичный) разрядами, принимающими значения {+, 0, –}. Например, “00000000” = “+–00+–“, “11111110” = “–+0+00”. Избыточность кода 8B/6T выше, чем у кода 4B/5B и составляет 36/28 = 729/256
= 2,85. Применяется в Fast Ethernet – 100BaseT4.
Скремблирование заключается в побитном вычислении выходной последовательности на основании значений бит исходной последовательности и уже вычисленных бит результата. Например, скремблер может вычислять для каждого бита следующее выражение: Bi=AiÅBi-5ÅBi-7, где Ai – i-й бит исходной последовательности, Bi – i-й бит результата скремблирования, Å – операция сложения по модулю два. Различные алгоритмы скремблирования отличаются разным количеством слагаемых и разным сдвигом между слагаемыми (в приведенном выше примере используется два слагаемых со сдвигами 5 и 7). Например, в ISDN используется два варианта скремблирования: со сдвигами 5 и 23, и со сдвигами 18 и 23.
Существуют специальные методы скремблирования, применяемые совместно определенными методами физического кодирования. Например, для улучшения кода AMI применяются методы B8ZS и HDB3. Метод B8ZS (Bipolar win 8-Zeros Substitution, биполярный с заменой 8 нулей) заменяет последовательности, состоящие из 8 нулей на “000V10V1”, где V – сигнал единицы запрещенной в данном такте полярности, а 1 – сигнал единицы корректной полярности. Если на 8 тактах приемник наблюдает три начальных нуля и два искажения полярности, то он заменяет эти 8 бит на 8 логических нулей. Метод HDB3 (High-Density Bipolar 3-Zeros, биполярный трехнулевой высокой плотности) заменяет последовательности из четырех идущих подряд нулей на один из четырех четырехразрядных биполярных кодов в зависимости от предыстории – полярности предыдущего импульса и предыдущей замены.
Самосинхронизирующиеся коды
Коды, позволяющие выделять синхросигнал из последовательности состояний линии, называются самосинхронизирующимися. При использовании таких кодов отпадает необходимость в отдельной синхронизации передатчика и приемника.
Одна из возможных реализаций самосинхронизирующих кодов – двухфазные коды, в каждом битовом интервале которых обязательно присутствует переход из одного состояния в другое.
Большинство технологий локальных сетей используют именно самосинхронизирующие коды: в
Ethernet применяется манчестерский код, в Token Ring
– вариант дифференциального манчестерского кода
Контроль передачи информации и сжатие данных
Самовосстанавливающиеся коды
Одним из средств борьбы с помехами являются самовосстанавливающиеся (корректирующие) коды, позволяющие не только обнаружить, но и исправить ошибки при приеме.
Пусть используется n-разрядный двоичный код. Ошибка при приеме кодовой комбинации состоит в том, что (под влиянием помехи) либо переданный нуль был принят, как единица, либо единица была принята, как нуль. Если в кодовой комбинации ошибка присутствует только в одном разряде, то такую ошибку будем называть одиночной, если в двух разрядах – двойной и т.д.
Если при передаче в качестве информационных используются все возможные кодовые комбинации, ошибки невозможно даже обнаружить: любая ошибка преобразует кодовую комбинацию в другую допустимую кодовую комбинацию. Для распознавания ошибок необходимо часть кодовых комбинаций зарезервировать для контроля ошибок. Для того, чтобы было можно обнаружить одиночную ошибку, достаточно в качестве информационных взять такие кодовые комбинации, которые различались бы между собой не менее, чем в двух знаках. Тогда одиночная ошибка в любой информационной кодовой комбинации приводила бы к появлению запрещенной кодовой комбинации. Для исправления одиночных ошибок, можно использовать код, информационные кодовые комбинации которого различаются не менее, чем в трех знаках. Тогда одиночная ошибка даст запрещенную кодовую комбинацию, отличающуюся от исходной в одном знаке, но отличающуюся от любой другой разрешенной комбинации не менее, чем в двух знаках. Соответственно, можно будет не только обнаружить ошибку, но и найти истинную передававшуюся кодовую комбинацию.
Аналогичным образом можно построить коды, обнаруживающие и исправляющие ошибки любой кратности. Для этого нужно лишь уменьшать долю информационных кодовых комбинаций среди всех возможных.
При таком подходе необходимо каждую принятую кодовую комбинацию сравнивать со всеми разрешенными комбинациями и, в случае совпадения, считать, что ошибки не было, а в противном случае считать истинной разрешенную комбинацию, отличающуюся от принятой в минимальном количестве разрядов. Это – довольно малоэффективный метод обнаружения и исправления ошибок.
Систематические коды
Другой подход к построению кодов – разделение разрядов кода на информационные и контрольные. Такие коды называются систематическими. Пусть всего в коде n разрядов, из них k – информационных и r – контрольных разрядов (n=k+r). Такой код может передавать N = 2k различных сообщений. Из r контрольных разрядов можно организовать 2r различных комбинаций. Для обнаружения и исправления одиночной ошибки нужно, во-первых, указать наличие/отсутствие ошибки и, во-вторых, указать номер разряда, в котором произошла ошибка.
Таким образом, чтобы в контрольных разрядах можно было передавать информацию для исправления одиночных ошибок, их количество должно удовлетворять неравенству 2r≥n+1 или 2n/(n+1) ≥N. Если достигается равенство: 2n/(n+1) = N, то количество контрольных разрядов, приходящихся на один информационный, будет наименьшим. Например, для N=4 различных сообщений (k=2) наименьшее значение n равно пяти (24/(4+1) = 3,2 < 4, а 25/6 ≈ 5,3 > 4). Значит, количество контрольных разрядов, необходимое для обнаружения и исправления одиночных ошибок r = n-k = 5-2 = 3.
Алгоритмы сжатия данных
В общем смысле под сжатием данных понимают такое их преобразование, что его результат занимает меньший объем памяти. При этом (по сравнению с исходным представлением) экономится память для их хранения и сокращается время передачи сжатых данных по каналам связи. Синонимы термина “сжатие” – упаковка, компрессия, архивация. Обратный процесс (получение исходных данных по сжатым) называется распаковкой, декомпрессией, восстановлением.
Качество сжатия характеризуется коэффициентом сжатия, равным отношению объема сжатых данных к объему исходных данных.
В зависимости от возможной точности восстановления исходных данных, различаю сжатие без потерь (данные восстанавливаются точно в исходном виде) и сжатие с потерями (восстановленные данные не идентичны исходным, но их различиями в том контексте, в котором эти данные используются, можно пренебречь). Сжатие с потерями применяется, например, для упаковки многоцветных фотографических изображений (алгоритм JPEG), звука (алгоритм MP3), видео (группа алгоритмов MPEG). При этом используются особенности человеческого восприятия: например, глаз человека не может различить два близких оттенка цвета, закодированных 24 битами, поэтому можно без видимых искажений уменьшить разрядность представления цвета.
Для многих разновидностей данных – текстов, исполняемых файлов и т.д.
– допустимо применение только алгоритмов сжатия без потерь.
Сжатие без потерь, в основном, базируется на двух группах методов: словарных и статистических. Словарные методы используют наличие повторяемых групп данных и, например, записывают первое вхождение повторяемого участка непосредственно, а все последующие вхождения заменяют на ссылку на первое вхождение. Другие словарные методы отдельно хранят словарь в явной форме и заменяют все вхождения словарных терминов на их номер в словаре.
Статистические методы используют тот факт, что частота появления в данных различных байтов (или групп байтов) неодинакова, следовательно, часто встречающиеся байты можно закодировать более короткой битовой последовательностью, а редко встречающиеся – более длинной. Часто в одном алгоритме используют и словарные, и статистические методы.
Алгоритм RLE
Самый простой из словарных методов – RLE (Run Length Encoding, кодирование переменной длины) умеет сжимать данные, в которых есть последовательности повторяющихся байтов. Упакованные RLE данные состоят из управляющих байтов, за которыми следуют байты данных. Если старший бит управляющего байта равен 0, то следующие байты (в количестве, записанном в семи младших битах управляющего байта) при упаковке не изменялись. Если старший бит равен 1, то следующий байт нужно повторить столько раз, какое число записано в остальных разрядах управляющего байта.
Например, исходная последовательность
00000000 00000000 00000000 00000000 11001100 10111111 10111011 будет закодирована в следующем виде (выделены управляющие байты):
10000100 00000000 00000011 11001100 10111111 10111011.
А, например, данные, состоящие из сорока нулевых байтов, будут закодированы всего двумя байтами: 1010 1000 00000000.
Алгоритм Лемпела-Зива
Наиболее широко используются словарные алгоритмы из семейства LZ, чья идея была описана Лемпелом и Зивом в 1977 году. Существует множество модификаций этого алгоритма, отличающихся способами хранения словаря, добавления слова в словарь и поиска слова в словаре.
Словом в этом алгоритме называется последовательность символов (не обязательно совпадающая со словом естественного языка). Слова хранятся в словаре, а их вхождения в исходные данные заменяются адресами (номерами) слов в словаре. Некоторые разновидности алгоритма хранят отдельно словарь и отдельно упакованные данные в виде последовательности номеров слов. Другие считают словарем весь уже накопленный результат сжатия. Например, сжатый файл может состоять из записей вида [a,l,t], где a – адрес (номер позиции), с которой начинается такая же строка длины l, что и текущая строка. Если a>0, то запись считается ссылкой на словарь и поле t (текст) в ней – пустое. Если a = 0, то в поле t записаны l символов, которые до сих пор в такой последовательности не встречались. Алгоритм сжатия заключается в постоянном поиске в уже упакованной части данных максимальной последовательности символов, совпадающей с последовательностью, начинающейся с текущей позиции. Если такая последовательность (длины > 3) найдена, в результат записывается ее адрес и длина. Иначе в результат записывается 0, длина последовательности и сама (несжатая) последовательность.
Кодирование Шеннона-Фано
Методы эффективного кодирования сообщений для передачи по дискретному каналу без помех, предложенные Шенноном и Фано, заложили основу статистических методов сжатия данных. Код Шеннона-Фано строится следующим образом: символы алфавита выписывают в таблицу в порядке убывания вероятностей. Затем их разделяют на две группы так, чтобы суммы вероятностей в каждой из групп были максимально близки (по возможности, равны). В кодах всех символов верхней группы первый бит устанавливается равным 0, в нижней группы – 1. Затем каждую из групп разбивают на две подгруппы с одинаковыми суммами вероятностей, и процесс назначения битов кода продолжается по аналогии с первым шагом. Кодирование завершается, когда в каждой группе останется по одному символу.
Качество кодирования по Шеннону-Фано сильно зависит от выбора разбиений на подгруппы: чем больше разность сумм вероятностей подгрупп, тем более избыточным оказывается код. Для дальнейшего уменьшения избыточности, используют кодирование крупными блоками – в качестве “символов” используются комбинации исходных символов сообщения, но и этот подход имеет те же ограничения. От указанного недостатка свободна методика кодирования Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов кода на символ сообщения. На первом шаге подсчитываются частоты всех символов в исходных данных. На втором шаге строятся новые коды (битовые последовательности) для каждого символа, так, чтобы никакие две разные последовательности не имели общего начала, например, три последовательности 0, 10, 110. удовлетворяют этому требованию. Хаффман предложил строить двоичное дерево символов, в корне которого находится наиболее частый символ, на расстоянии 1 от корня – следующие по частоте символы, и так далее. На основе такого дерева коды для символов получаются путем выполнения простой процедуры обхода дерева. Код представляет собой путь от корня до символа, в котором 1 означает переход по левой ветви, а 0 – по правой. Такой способ построения гарантирует нужное свойство кодов. Наконец, на последнем шаге в выходные данные записывается построенное дерево, а за ним следуют закодированные данные.
Алгоритм Хаффмана обеспечивает высокую скорость упаковки и распаковки, но степень сжатия, достигаемая при его использовании, довольно невелика. Одним из недостатков этого алгоритма является необходимость двух проходов по данным – на первом проходе подсчитываются частоты, строится дерево и формируются коды, а на втором выполняется собственно кодирование. Этого недостатка лишен адаптивный алгоритма Хаффмана, пересчитывающий частоты символов (и, соответственно, изменяющий коды) по мере поступления данных.